[AAAI 2025] InstructAvatar: Text-Guided Emotion and Motion Control for Avatar Generation
 Example sentence pairs in the MultiSim dataset in English, Japanese, Urdu, and Russian
Example sentence pairs in the MultiSim dataset in English, Japanese, Urdu, and RussianAbstract
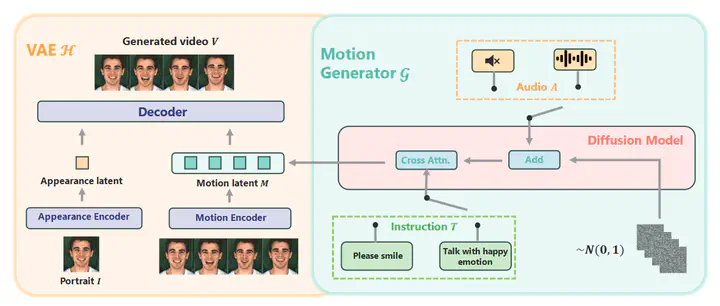
Recent talking avatar generation models have made strides in achieving realistic and accurate lip synchronization with the audio, but often fall short in controlling and conveying detailed expressions and emotions of the avatar, making the generated video less vivid and controllable. In this paper, we propose a novel text-guided approach for generating emotionally expressive 2D avatars, offering fine-grained control, improved interactivity and generalizability to the resulting video. Our framework, named InstructAvatar, leverages a natural language interface to control the emotion as well as the facial motion of avatars. Technically, we design an automatic annotation pipeline to construct an instruction-video paired training dataset, equipped with a novel two-branch diffusion-based generator to predict avatars with audio and text instructions at the same time. Experimental results demonstrate that InstructAvatar produces results that align well with both conditions, and outperforms existing methods in fine-grained emotion control, lip-sync quality, and naturalness.
Yuchi Wang
PhD Student of Artificial Intelligence
My research interests include multimodal learning, generative AI and large language models.