 InstructAvatar: Text-Guided Emotion and Motion Control for Avatar Generation
InstructAvatar: Text-Guided Emotion and Motion Control for Avatar Generation
InstructAvatar: Text-Guided Emotion and Motion Control for Avatar Generation
| |
|
|
| |
|
|
| |
|
|
| |
|
|
Recent talking avatar generation models have made strides in achieving realistic and accurate lip synchronization with the audio, but often fall short in controlling and conveying detailed expressions and emotions of the avatar, making the generated video less vivid and controllable.
In this paper, we propose a novel text-guided approach for generating emotionally expressive 2D avatars , offering fine-grained control, improved interactivity and generalizability to the resulting video. Our framework, named InstructAvatar, leverages a natural language interface to control the emotion as well as the facial motion of avatars. We design an automatic annotation pipeline to construct an instruction-video paired training dataset, equipped with a novel two-branch diffusion-based generator to predict avatars with audio and text instructions at the same time.
Experimental results demonstrate that InstructAvatar produces results that align well with both conditions, and outperforms existing methods in fine-grained emotion control, lip-sync quality, and naturalness.
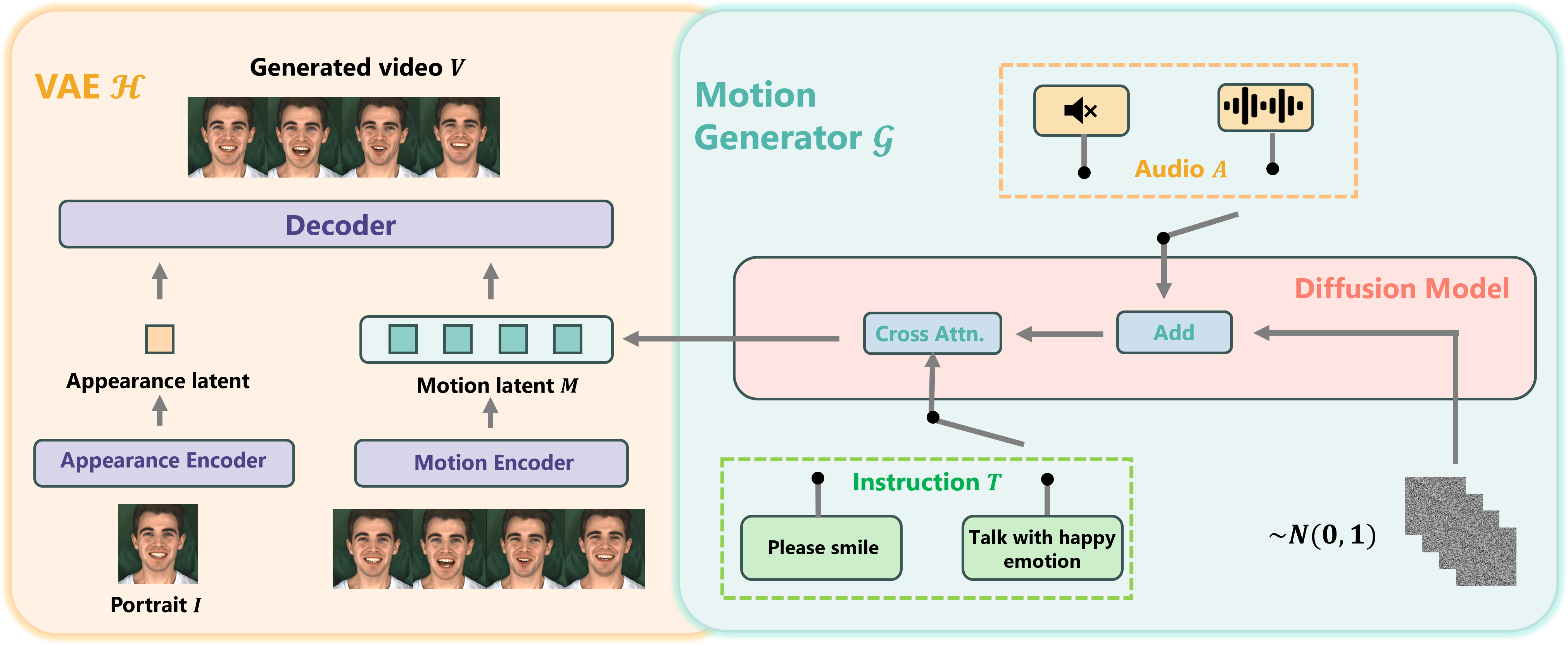
The InstructAvatar consists of two components: VAE to disentangle motion information from the video and a diffusion model based motion generator to generate the motion latent conditioned on audio and instruction. As we have two types of data, two switches in instruction and audio are designed. During inference, we iteratively denoise Gaussian noise to obtain the predicted motion latent. Together with the user-provided portrait, the resulting video is generated by the decoder of the VAE.
Qualitative comparison with baselines. It shows that InstructAvatar achieves well lip-sync quality and emotion controllability. Additionally, the outputs generated by our model exhibit enhanced naturalness and effectively preserve identity characteristics. It's also worth mentioning that our model infers talking emotion solely based on text inputs, which intuitively poses a more challenging task. Additionally, our model supports a broader scope of instructions beyond high-level emotion types, which is absent for most baselines.
Additional outcomes concerning text-guided emotional talking control are presented above. We can see that our model exhibits precise emotion control ability, with the generated results appearing natural. Furthermore, InstructAvatar supports fine-grained control and demonstrates reasonable generalization ability beyond the domain.
We show more results about facial motion control above. It is evident that InstructAvatar exhibits remarkable proficiency in following instructions and preserving identity. Furthermore, the generated results appear natural and robust with variations in the provided portrait. Moreover, our model demonstrates fine-grained control capability and performs effectively in out-of-domain scenarios.
InstructAvatar is designed to advance AI research on talking avatar generation. Responsible usage is strongly encouraged, and we discourage users from employing our model to generate intentionally deceptive content or engage in other inauthentic activities. To prevent misuse, adding watermarks is a common approach. Moreover, as a generative model, our results can be utilized to construct artificial datasets and train discriminative models.
@misc{wang2024instructavatar,
title={InstructAvatar: Text-Guided Emotion and Motion Control for Avatar Generation},
author={Yuchi Wang and Junliang Guo and Jianhong Bai and Runyi Yu and Tianyu He and Xu Tan and Xu Sun and Jiang Bian},
year={2024},
eprint={2405.15758},
archivePrefix={arXiv},
primaryClass={cs.CV}
}